
用AMD 5600xt 6g显存显卡来跑Stable Diffusion真的是要了命了。
手动部署
参考AUTOMATIC1111的AMD显卡安装与使用说明。Nvidia显卡部署更方便,但推荐使用整合包。
第一步:安装Python 3.10.6和Git,安装Python时勾选添加PATH或自行添加。
第二步:运行下面指令来获取并更新
git clone https://github.com/lshqqytiger/stable-diffusion-webui-directml && cd stable-diffusion-webui-directml && git submodule init && git submodule update第三步:运行文件夹内的webui-user.bat来启动程序,如果卡住按回车。等待浏览器启动软件的web界面。
注意
如果显存低于6g,可修改webui-user.bat,修改添加
set COMMANDLINE_ARGS=--opt-sub-quad-attention --lowvram --disable-nan-check也可以在网上搜索其他参数,保证能正常使用。
手动部署成功后还需要在设置中切换语言,使用起来很麻烦,还需要手动安装各种辅助插件来帮助使用。不推荐。
使用整合包
推荐使用秋葉aaaki制作的Stable Diffusion A卡专用整合包(DirectML)
下载安装后可自动更新文件和补全运行环境直接使用。
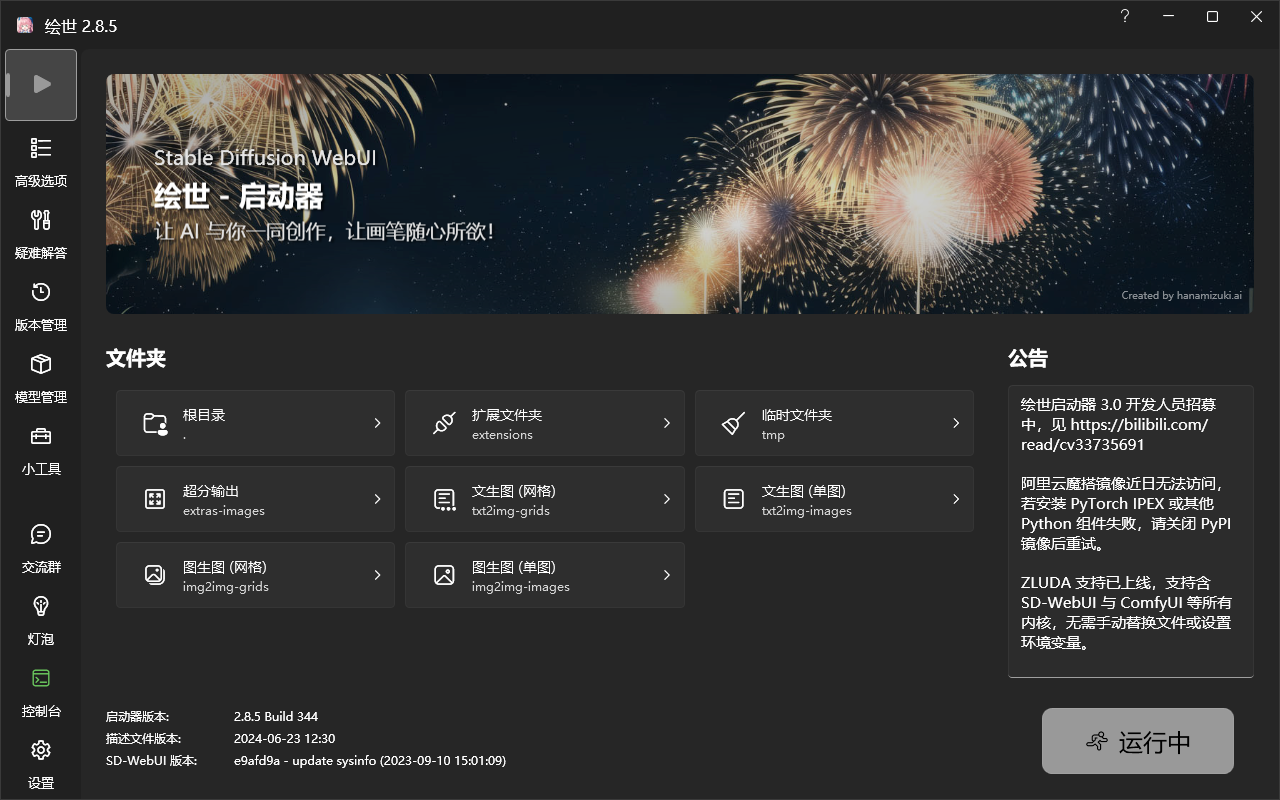
启动器中有不少功能,可以更方便的修改设置和下载模型。
启动后则自动打开界面,如下:
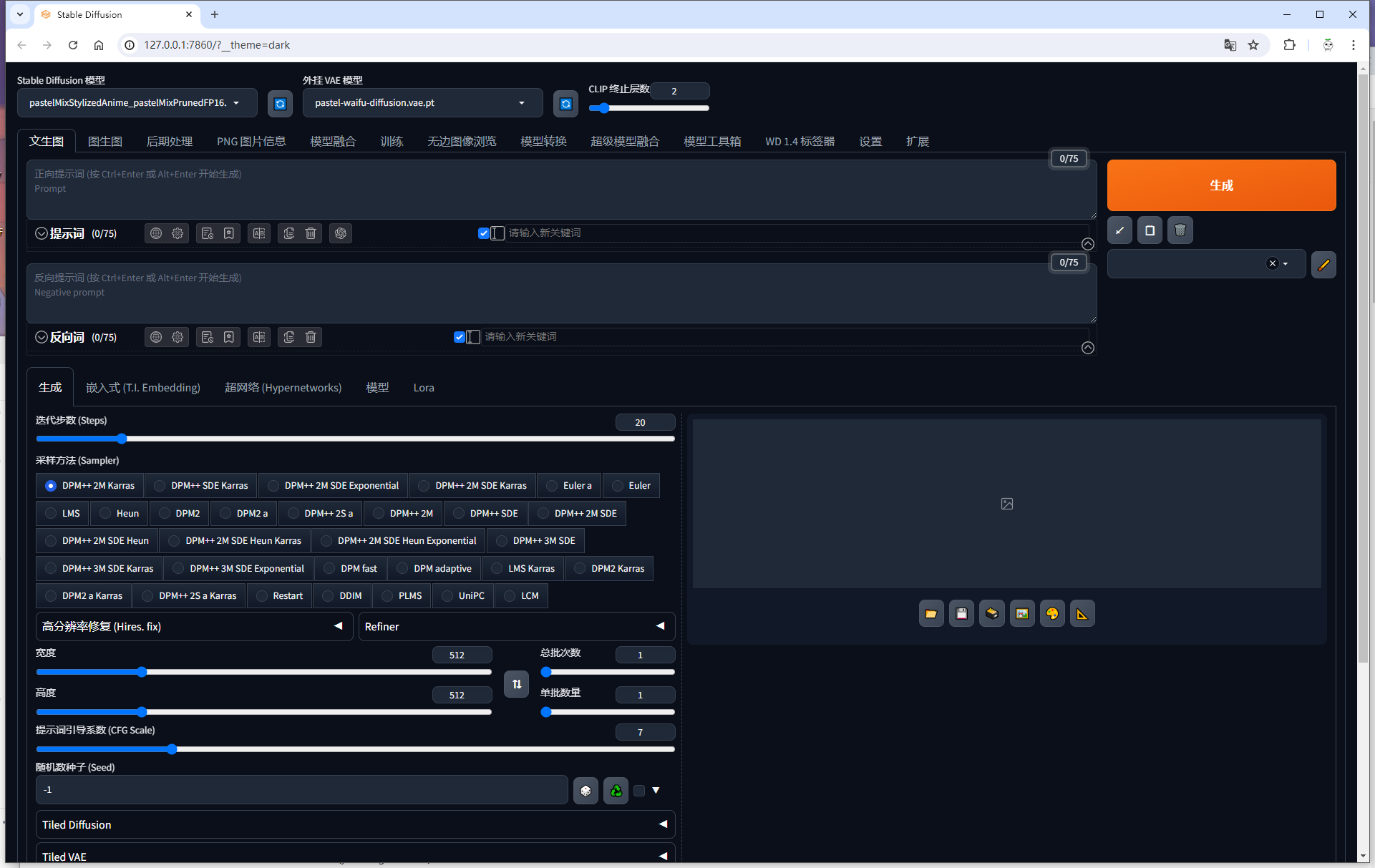
简单描述
模型等资源下载网站推荐:Civitai、Hugging Face
新添加的模型如果没有显示可以点旁边的刷新载入按钮。
Stable Diffusion 模型:最上方左上角Stable Diffusion 模型为基础的绘画模型,可以切换不同的模型,可以简单理解为切换不同的绘画风格,例如油画风格、漫画风格、写实风格等等。你可以在上方网站中搜索查看不同模型画出来的图片,来选择下载想要的风格。下载的模型文件放在程序文件夹\models\Stable-diffusion文件夹中。
外挂 VAE 模型:最上方的外挂 VAE 模型可以理解成画面的滤镜,不少模型的下载介绍页面中都会给出相应的推荐或者直接内置,一般不需要修改或者根据要求修改。下载的模型文件放在程序文件夹\models\VAE文件夹中。
图生文:使用最多的功能,使用许多提示词和反向词生成输入画面的内容,尽可能的具象和抽象并存的描述整个画面。提示词就是画面中应该要包含的词汇,反向词则是画面中尽可能避免出现的词汇,例如添加手指错误等词汇来避免手指错误。
下方的迭代步数采样方法等配置默认或者根据模型说明的要求来修改,也可以自行尝试或者按照网友的推荐。
Lora:在反向词输入框的下方,有Lora模型的配置页面,Lora模型可以理解为一种更详细的特征。例如指定画出来的女孩就是某位明星,你就需要下载这位明星的Lora模型。下载下来的模型文件放过在程序文件夹\models\Lora文件夹中。如果在绘画中需要使用这个Lora模型时,需要点进Lora模型的配置页面,选择需要的模型,这时提示词中就会增加一个提示词,且后面会跟随一个参数,可以适量增大参数例如修改为1.5,来让绘画结果更加接近这个模型的特征。
WD1.4标签器:选择图片就会给出这张图片的提示词信息,可以用这个功能来获取一张图片的提示词并发送到文生图进行进一步修改来画出一张跟原图类似的图片。
实际演示
使用pastelMix模型,外挂VAE模型为pastel-waifu-diffusion,采样方法DPM++ 2M Karras,放大算法Latent,重绘幅度0.7。
从网络中下载一张原神中妮露的图片

将图片放进WD1.4标签器生成提示词后发送到文生图并适当修改提示词,选择Lora模型中下载的妮露模型。点击等待生成后如下图所示。
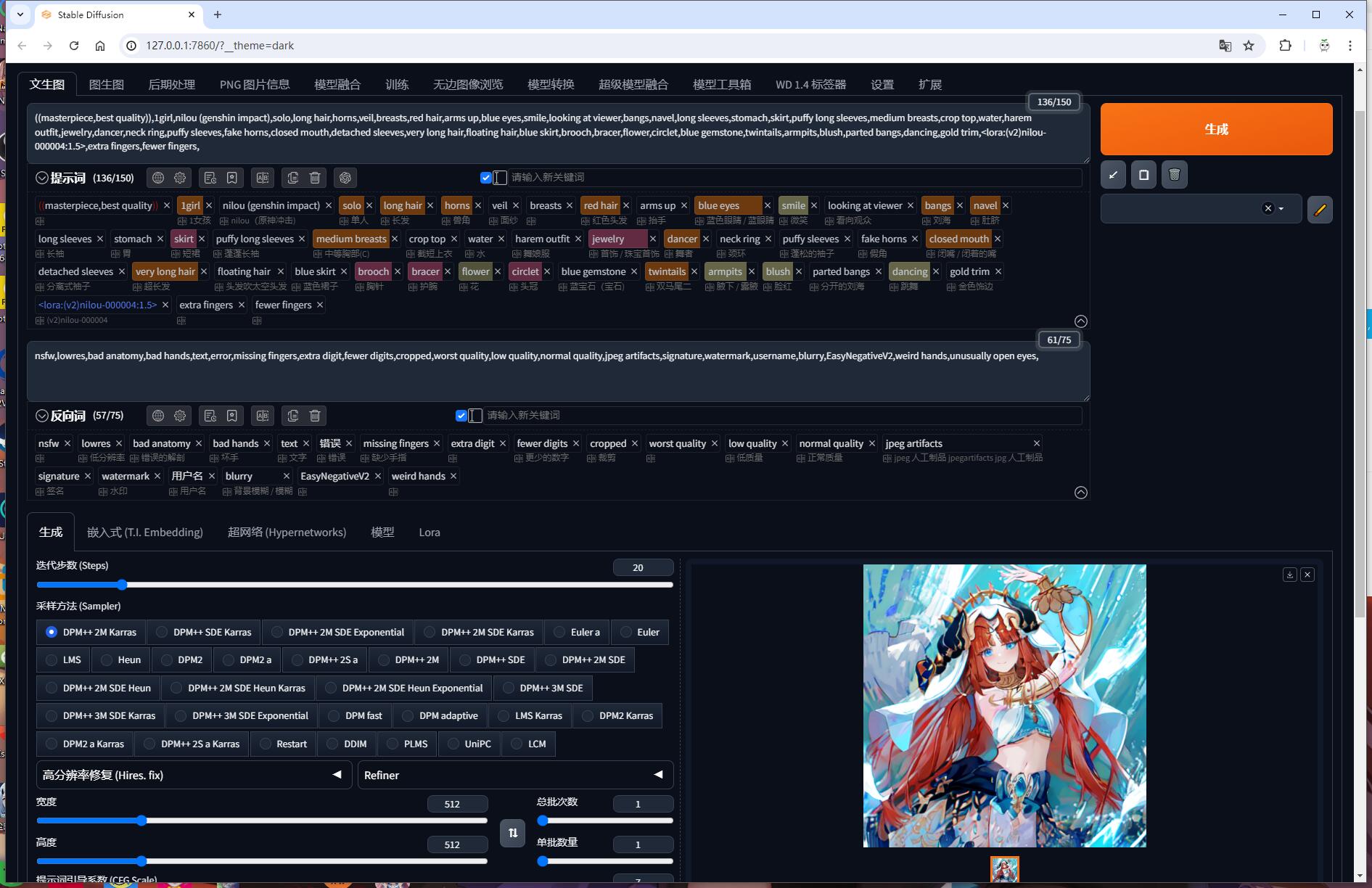
这样就快速简单的生成一张特定的AI绘画图片了。
性能足够的话可以批量生成,选择质量好的。如果不想让每一张画面变化幅度太大,可以指定或者使用之前图片的seed种子。

模型训练制作
我5600xt我也配??等我什么时候有好显卡再说吧。